※当ブログでは商品・サービスのリンク先にプロモーションを含みます。ご了承ください。
PDFドキュメントから特定のページを抽出するために、ドキュメントビューアソフトウェアを使用する必要はありません。実際、Google Chromeだけでも、1つ以上の特定のページを選択して、それらを新しいPDFドキュメントとして抽出できます。これを実現する方法は次のとおりです。
ページコンテンツ
GoogleChromeを使用してPDFから特定のページを抽出する方法
1.ChromeなどのブラウザでPDFドキュメントを起動します。これを行うには、ファイルを右クリックして>[プログラムから開く]>[GoogleChrome]を選択します。
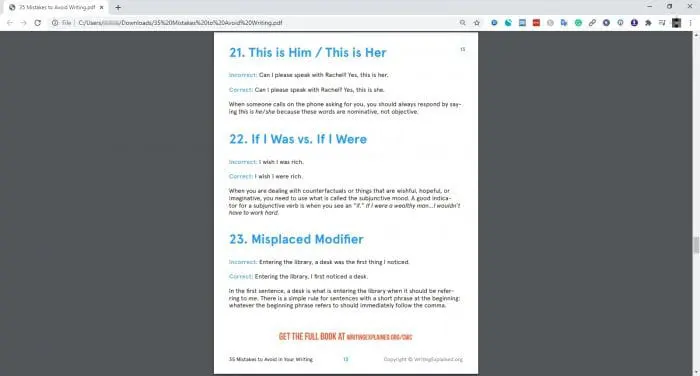
2. [印刷]ボタンをクリックするか、 CTRL+Pを押します。
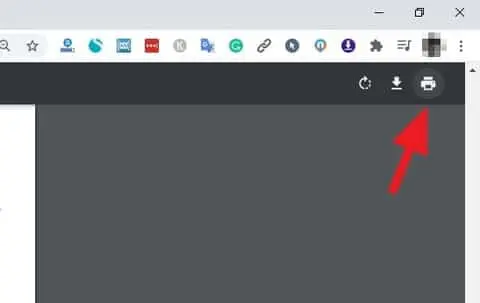
3. [保存先]で、[ PDFとして保存]を選択します。
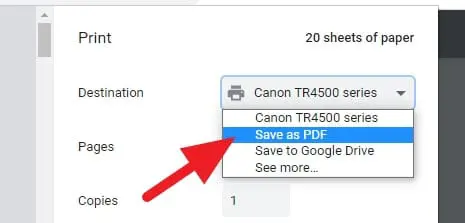
4. [ページ]で、[カスタム]を選択します。
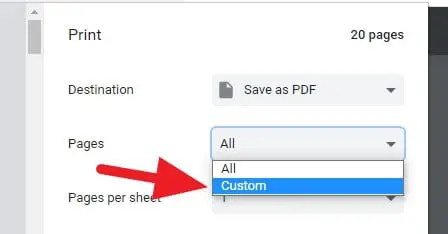
5.抽出するページを選択します。
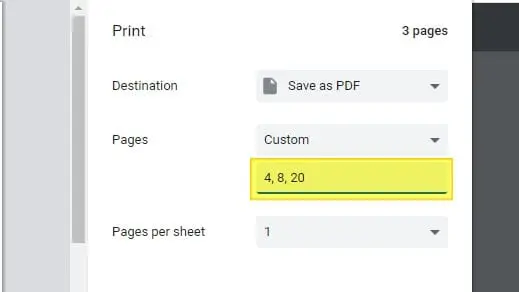
6.[保存]をクリックします。
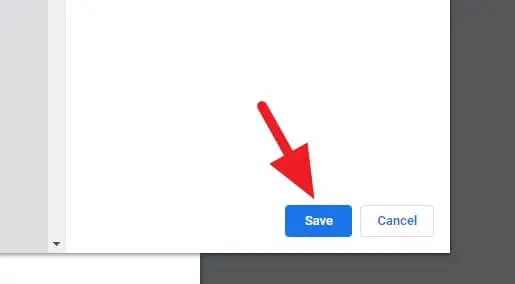
7.名前を付けて、[保存]をクリックします。
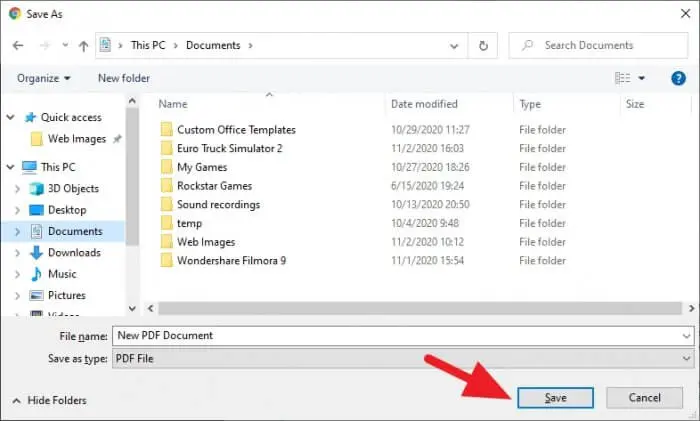
これで、前に選択したページだけを含む新しいPDFファイルが抽出されました。
まとめ
おめでとうございます、これで完了です。これで、PDFをExcel、CSV、XML、またはHTMLに変換できます。
-
 PDFMacでPDFにメモおよび吹き出し(会話)などの注釈をつける方法【プレビュー・AdobeAcrobatDC】
PDFMacでPDFにメモおよび吹き出し(会話)などの注釈をつける方法【プレビュー・AdobeAcrobatDC】 -
 PDFGoogleドライブでPDFファイルをパスワードで保護する方法
PDFGoogleドライブでPDFファイルをパスワードで保護する方法 -
 PDFAmazonで購入したKindle形式(キンドル)の電子書籍ファイル形式をPDFに変換・転送する方法
PDFAmazonで購入したKindle形式(キンドル)の電子書籍ファイル形式をPDFに変換・転送する方法 -
 PDFmacOSでPDFのデフォルトアプリケーション・勝手に開くアプリを変更する方法 【Adobe Acrobat Readerなど】
PDFmacOSでPDFのデフォルトアプリケーション・勝手に開くアプリを変更する方法 【Adobe Acrobat Readerなど】 -
 PDFPDFファイルにしかない表/テーブルを抽出・読み込みする方法
PDFPDFファイルにしかない表/テーブルを抽出・読み込みする方法 -
 PDFPDFをWord形式に変換・コンバート(WordでPDFを開く)ができない場合の代わりの方法まとめ
PDFPDFをWord形式に変換・コンバート(WordでPDFを開く)ができない場合の代わりの方法まとめ -
 PDFpdf編集が可能なフリーかつインストール不要な無料オンラインPDFエディターまとめ!ブラウザのみで対応!
PDFpdf編集が可能なフリーかつインストール不要な無料オンラインPDFエディターまとめ!ブラウザのみで対応! -
 PDFGoogleフォームを印刷可能なPDFファイル化にすばやく変換する方法
PDFGoogleフォームを印刷可能なPDFファイル化にすばやく変換する方法